👉 This article is also published on Towards Data Science blog.
Introduction
Differential privacy (DP) is a rigorous mathematical framework that permits the analysis and manipulation of sensitive data while providing robust privacy guarantees.
DP is based on the premise that the inclusion or exclusion of a single individual should not significantly change the results of any analysis or query carried out on the dataset as a whole. In other words, the algorithm should come up with comparable findings when comparing these two sets of data, making it difficult to figure out anything distinctive about that individual. This safety keeps private information from getting out, but still lets useful insights be drawn from the data.
Differential privacy initially appeared in the study “Differential Privacy” by Cynthia [1] while she was working at Microsoft Research.
Examples of How Differential Privacy Safeguards Data
Example 1
In this part, I’ll use an example from [2] to help you understand why differential privacy is important. In a study that looks at the link between social class and health results, researchers ask subjects for private information like where they live, how much money they have, and their medical background.
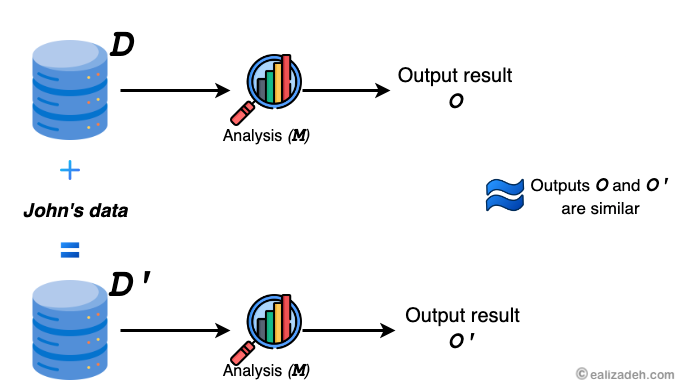
John, one of the participants, is worried that his personal information could get out and hurt his applications for life insurance or a mortgage. To make sure that John’s worries are taken care of, the researchers can use differential privacy. This makes sure that any data that is shared won’t reveal specific information about him. Different levels of privacy can be shown by John’s “opt-out” situation, in which his data is left out of the study. This protects his anonymity because the analysis’ results are not tied to any of his personal details.
Differential privacy seeks to protect privacy in the real world as if the data were being looked at in an opt-out situation. Since John’s data is not part of the computation, the results regarding him can only be as accurate as the data available to everyone else.
A precise description of differential privacy requires formal mathematical language and technical concepts, but the basic concept is to protect the privacy of individuals by limiting the information that can be obtained about them from the released data, thereby ensuring that their sensitive information remains private.
Example 2
The U.S. Census Bureau used a differential privacy framework as a part of its disclosure avoidance strategy to strike a compromise between the data collection and reporting needs and the privacy concerns of the respondents. Check [3] to find more information about the confidentiality protection provided by the U.S. Census Bureau. Moreover, [4] provides an explanation of how DP was utilized in the 2020 US Census data here.
Definition and key concepts
The meanining of “Differential” within the realm of DP?
The term “differential” privacy refers to its emphasis on the dissimilarity between the results produced by a privacy-preserving algorithm on two datasets that differ by just one individual’s data.
Mechanism M
A mechanism M is a mathematical method or process that is used on the data to make sure privacy is maintained while still giving useful information.
Epsilon (\epsilon)
\epsilon is a privacy parameter that controls the level of privacy given by a differentially private mechanism. In other words, \epsilon regulates how much the output of the mechanism can vary between two neighboring databases and measures how much privacy is lost when the mechanism is run on the database [5].
Stronger privacy guarantees are provided by a smaller \epsilon, but the output may be less useful as a result [6]. \epsilon controls the amount of noise added to the data and shows how much the output probability distribution can change when the data of a single person is altered.
Delta (\delta)
\delta is an extra privacy option that lets you set how likely it is that your privacy will be compromised. Hence, \delta controls the probability of an extreme privacy breach, where the added noise (controlled by \epsilon) does not provide sufficient protection.
\delta is a non-negative number that measures the chance of a data breach. It is usually very small and close to zero. This change makes it easier to do more complicated studies and machine learning models while still protecting privacy see [6].
If \delta is low, there is less of a chance that someone’s privacy is going to get compromised. But this comes at a cost. If \delta is too small, more noise might be introduced into the data, diminishing the quality of the end-result. \delta is one parameter to consider, but it must be balanced with epsilon and the data’s practicality.
Unveiling the Mathematics behind Differential Privacy
Consider two databases, D and D', that differ by only one record.
Formally, a mechanism M is \epsilon-differentially private if, for any two adjacent datasets D and D', and for any possible output O, the following holds:
\text{Pr}[\text{M}(D) \in O] \leq \exp(\epsilon) \times \text{Pr}[\text{M}(D') \in O] \tag{1}
However, we can reframe the Equation 1 in terms of divergences, resulting in Equation 2.
\text{div}[M(D) \, || \, M(D')] \leq \epsilon \tag{2}
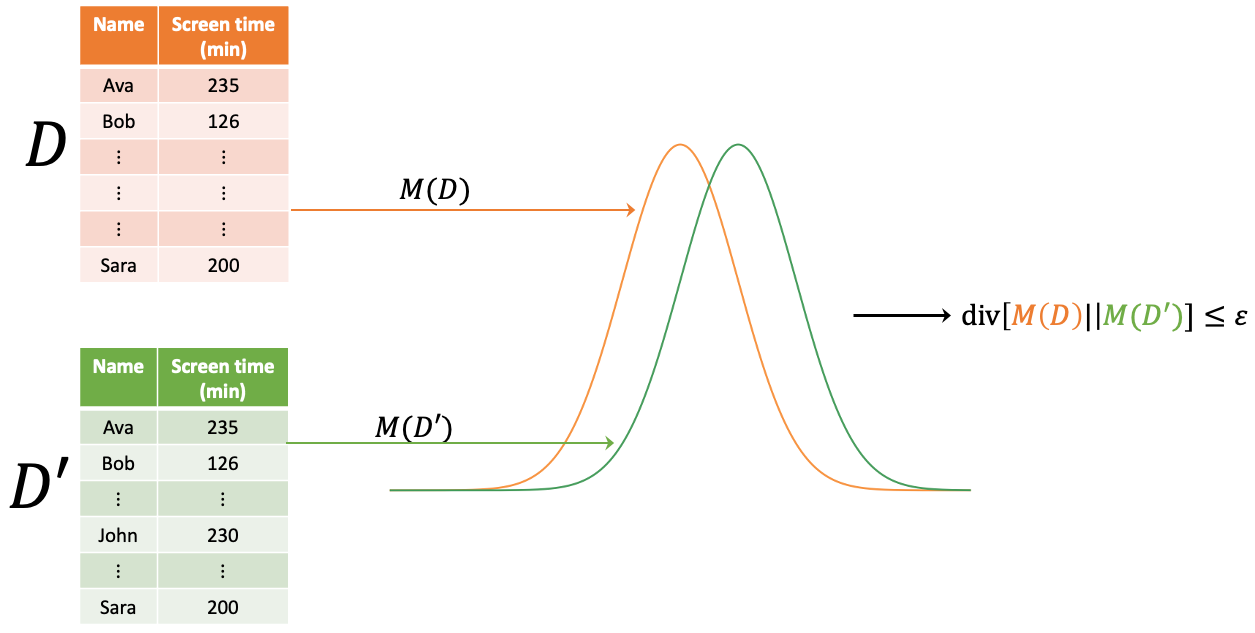
Here \text{div}[\cdot \, || \, \cdot] denotes the Rényi divergence.1
(\epsilon, \delta)-DP Definition
A randomized M is considered (\epsilon, \delta)-differentially private if the probability of a significant privacy breach (i.e., a breach that would not occur under \epsilon-differential privacy) is no more than \delta. More formally, a mechanism M is (\epsilon, \delta)-differentially private if
\text{Pr}[\text{M}(D) \in O] \leq \exp(\epsilon) \times \text{Pr}[\text{M}(D') \in O] + \delta \tag{3}
If \delta = 0, then (\epsilon, \delta)-DP is reduced to a \epsilon-DP.
(\epsilon, \delta)-DP mechanism may be thought of informally as \epsilon-DP with the probability of 1 - \delta.
Properties of Differential Privacy
Post-processing immunity
The differentially private output can be subjected to any function or analysis, and the outcome will continue to uphold the original privacy assurances. For instance, if you apply a differentially private mechanism to a dataset and then take the average age of the individuals in the dataset, the resulting average age will still be differentially private and will provide the same level of privacy assurances as the output it was originally designed to provide.
Thanks to the post-processing feature, we can use differentially private mechanisms in the same way as generic ones. Hence, it is possible to combine several differentially private mechanisms without sacrificing the integrity of differential privacy.
Composition
When multiple differentially private techniques are used on the same data or when queries are combined, composition is the property that ensures the privacy guarantees of differential privacy still apply. Composition can be either sequential or parallel. If you apply two mechanisms, M_1 with \epsilon_1-DP and M_2 with \epsilon_2-DP on a dataset, then the composition of M_1 and M_2 is at least (\epsilon_1 + \epsilon_2)-DP.
Despite composition’s ability to protect privacy, the composition theorem makes clear that there is a ceiling; as the value of \epsilon rises, so does the amount of privacy lost whenever a new mechanism is employed. If \epsilon becomes too large, then differential privacy guarantees are mostly meaningless [5].
Robustness to auxiliary information:
Differential privacy is resistant to auxiliary information attackers, which means that even if an attacker has access to other relevant data, they will not be able to learn anything about a person from a DP output. For instance, if a hospital were to share differentially private information regarding individuals’ medical situations, an attacker with access to other medical records would not be able to greatly increase their knowledge of a given patient from the published numbers.
Common Misunderstandings
The notion of differential privacy has been misunderstood in several publications, especially during its early days. [7] wrote a short paper to correct some widespread misunderstandings. Here are a few examples of common misunderstandings:
- DP is not an algorithm but rather a definition. DP is a mathematical guarantee that an algorithm must meet in order to disclose statistics about a dataset. Several distinct algorithms meet the criteria.
- Various algorithms can be differentially private while still meeting various requirements. If someone claims that differential privacy, a specific requirement on ratios of probability distributions, is incompatible with any accuracy target, they must provide evidence for that claim. This means proving that there is no way a DP algorithm can perform to some specified standard. It’s challenging to come up with that proof, and our first guesses about what is and isn’t feasible are often off.
- There are no “good” or “bad” results for any given database. Generating the outputs in a way that preserves privacy (perfect or differential) is the key.
Conclusion
DP has shown itself as a viable paradigm for the protection of data privacy, which is particularly important in this day and age, when machine learning and big data are becoming more widespread. Several key concepts were covered in this essay, including the various DP control settings like \epsilon and \delta. In addition, we provided several mathematical definitions of the DP. We also explained key features of the DP and addressed some of the most common misconceptions.
Get new posts by email
Occasional writing on ML, statistics & AI engineering. No spam, unsubscribe anytime.
References
Footnotes
See the paper Renyi Differential Privacy by Ilya Mironov for more information.↩︎
Citation
@online{alizadeh2023,
author = {Alizadeh, Esmaeil},
title = {The {ABCs} of {Differential} {Privacy}},
date = {2023-04-27},
url = {https://ealizadeh.com/blog/abc-of-differential-privacy/},
langid = {en}
}